
Task 1: Post-editing and rescoring of automatic speech recognition results
Task definition
The goal of this task is to create a system for converting a sequence of words from a specific automatic speech recognition (ASR) system into another sequence of words that more accurately describes the actual spoken utterance. The training data will consist of utterance pairs each pair containing an utterance generated by the output of the ASR and an utterance containing the correct transcription of the utterance.
The ASR system used to create the training data is going to be the same one used during the evaluation procedure. That means that the solution to this task has to be able to correct the specific errors that this one specific system makes. It doesn't need to fix errors in any system that it hasn't seen.
For simplicity, the output of both the ASR and the required reference is going to be in normalized form: no punctuation, no capitalization and no digits, symbols or abbreviations. Just a simple sequence of words.
Description and motivation
ASR systems are used to convert audio recordings of speech into text. Just like most machine learning systems, ASR makes mistakes. A common way of expressing this is through the Word Error Rate (WER), which is equivalent to the ratio number of words mistakenly substituted, deleted or inserted with regard to the number of words in the correct transcript of a particular utterance. One of the most often used research goals is the reduction of this value within specific contexts.
This error can be reduced either by improving the internal mechanisms and models of the system itself, but a very popular method used in various problems involving a text output is post-editing [1, 3, 4, 6, 7]. This means using various external techniques to convert the raw text output of the system into a more correct version. A few motivating factors for the post-editing approach are given below.
A typical ASR system is usually created using a combination of an acoustic and a language model, where the language model is often based on a basic statistical n-gram approach. Errors produced by such a system are often trivial and easy to spot. One might argue that using a better language model could fix this problem, but this is often intractable as the system is expected to produce a language score of many hundreds of acoustic-level hypotheses at any given time. Even the more modern end-to-end ASR systems often suffer from this same issue, as the model size is already extremely large in order to contain both the acoustic and language parts in the same deep neural network.
Given the lack of constraints of the typical ASR system, a post-editing solution can take any design approach into account. It can be as simple as using a larger n-gram language model or as complicated as a combination of several NLP-oriented subsystems targeted at fixing specific language problems. It would be especially interesting to explore the new recurrent neural network based language models like BERT or other similar seq2seq approaches.
Finally, it turns out that a form of post-editing is actually a common approach used in many state-of-the-art results [8, 9] as a way of getting around the limitations of online speech recognition process. This technique is commonly referred to as re-scoring and it utilized more than just a single best output of the ASR system. It relies either on the N-best outputs (usually ~100 per utterance) or a more efficient data structure known as the lattice. The N-best approach works by simply taking the new model and re-scoring each hypothesis of the N-best hypotheses, which leads to a new ordering and a new sentence ending up as the best result.
The lattice approach is a bit more involved. A lattice is a connected graph where each arc emits a word with a specific weight attached to it. A path starting from a specific state in the graph and ending up in another specified state has a score calculated as the combination of the consecutive weights of the arcs used to traverse it. It is equivalent to the sequence and initial score of the N-best approach discussed above, but much more compact and efficient. Furthermore, each weight can be decomposed into its acoustic and language model components, which makes the re-scoring even better, by saving the acoustic model information in the final score. A lattice oracle is the path within the lattice that is closest to the reference output. A lattice will not contain every possible word sequence, so the lattice oracle error rate is usually >0%.
Training data
The ASR system used to generate the transcripts was trained on the Clarin-PL studio corpus. While the ASR outputs for the training data is not very useful for this task (it will be mostly without errors), it is provided just in case. The test and development data is much more useful but not too large in this case. Finally, the same system is applied to a larger Polish Parliament corpus from the last year's competition.
Each set contains the following files:
- 1-best output - each utterance containing a single best transcript of the ASR output
- n-best output - each utterance containing up to 100 best alternative hypotheses of the ASR output
- lattice output - each utterance containing a list of arcs forming a lattice of the ASR output
- each line contains the following fields: start node, end node, words, language weight, acoustic weight, list of phonetic-level states
- reference - file similar to the 1-best output, but containing the actual reference transcript
Download package contains:
- Clarin-PL training set
- WER 9.59%, lattice oracle WER 3.75%
- Clarin-PL test set
- WER 12.08%, lattice oracle WER 4.72%
- Clarin-PL dev set
- WER 12.39%, lattice oracle WER 4.93%
- Polish parliament corpus
- WER 45.57%, lattice oracle WER 30.71%
This file has been updated on 24.03.2020!
- WER 45.57%, lattice oracle WER 30.71%
You are free to use other data to improve the capabilities of your solution. For example, you can use the Polish Sejm Corpus for language modeling [5]: http://clip.ipipan.waw.pl/PSC.
The output above was created using the \textit{tri3b} model from the ClarinStudioKaldi setup available online [2]: https://github.com/danijel3/ClarinStudioKaldi
You can also use a dataset, from a similar challenge performed last year [10], available at: https://gonito.net/gitlist/asr-corrections.git/ (thanks to Marek Kubis). Note that the data in that challenge used a different ASR system, so the data may or may not be useful for improving results of this challenge.
Evaluation data
Please download the evaluation data below:
The evaluation data is generated from the soon to be published PINC (https://pincproject2020.wordpress.com/) dataset.
Evaluation procedure
The evaluation will be carried out using random, yet unknown recordings using the same ASR system used to prepare the training data. Participants will be provided with a file containing a collection of ASR outputs in the format described in the training section. They will have to create file containing the final corrected output, one line per utterance in the similar format as the 1-best output.
The evaluation will be carried out using the NIST SCLITE package to determine the Word Error Rate (WER) of the individual submissions. Word error rate is defined as the number of edit-distance errors (deletions, substitutions, insertions) divided by the length of the reference:
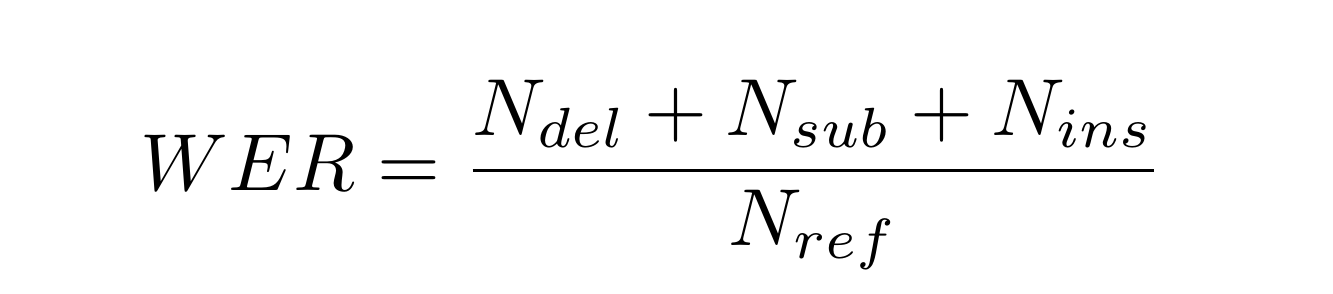
You are allowed any number of submissions, but only last three will be counted for the given team.
Task introduction video
References
[1] Youssef Bassil and Mohammad Alwani. Post-editing error correction algo- rithm for speech recognition using bing spelling suggestion. arXiv preprint arXiv:1203.5255, 2012.
[2] Danijel Koržinek, Krzysztof Marasek, Lukasz Brocki, and Krzysztof Wolk. Polish read speech corpus for speech tools and services. arXiv preprint arXiv:1706.00245, 2017.
[3] WonKee Lee, Jaehun Shin, and Jong-hyeok Lee. Transformer-based auto- matic post-editing model with joint encoder and multi-source attention of decoder. WMT 2019, page 112, 2019.
[4] António V Lopes, M Amin Farajian, Gonçalo M Correia, Jonay Trenous, and André FT Martins. Unbabel’s submission to the wmt2019 ape shared task: Bert-based encoder-decoder for automatic post-editing. arXiv preprint arXiv:1905.13068, 2019.
[5] Maciej Ogrodniczuk. The Polish Sejm Corpus. In Proceedings of the Eighth International Conference on Language Resources and Evaluation, LREC 2012, pp. 2219–2223, Istanbul, Turkey, 2012. ELRA
[6] Maciej Ogrodniczuk. Polish Parliamentary Corpus. In Darja Fišer, Maria Eskevich, and Franciska de Jong, editors, Proceedings of the LREC 2018 Workshop ParlaCLARIN: Creating and Using Parliamentary Corpora, pp. 15–19, Paris, France, 2018. European Language Resources Association (ELRA).
[7] Dimitar Shterionov, Joachim Wagner, and Félix do Carmo. Ape through neural and statistical mt with augmented data: Adapt/dcu submission to the wmt 2019 ape shared task. small, 268:840, 2019.
[8] Thuy Vu and Gholamreza Haffari. Automatic post-editing of machine trans- lation: A neural programmer-interpreter approach. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3048–3053, 2018.
[9] Wayne Xiong, Lingfeng Wu, Fil Alleva, Jasha Droppo, Xuedong Huang, and Andreas Stolcke. The microsoft 2017 conversational speech recognition system. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5934–5938. IEEE, 2018.
[10] Hainan Xu, Tongfei Chen, Dongji Gao, Yiming Wang, Ke Li, Nagendra Goel, Yishay Carmiel, Daniel Povey, and Sanjeev Khudanpur. A pruned rnnlm lattice-rescoring algorithm for automatic speech recognition. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5929–5933. IEEE, 2018.
[11] Kubis, M., Vetulani, Z., Wypych, M., Ziętkiewicz, T.: Open Challenge for Correcting Errors of Speech Recognition Systems, [in:] Proceedings of the 9th Language and Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics, pp. 219-223, Wydawnictwo Nauka i Innowacje, Poznań, Poland, 2019